Requirements
For questions or comments, e-mail us:
Any Windows version supporting .NET Framework 2.0. Only supports W3C XML schemas.
Download and unzip in directory of choice, no installation required, ![]() Download Validation Tool
Download Validation Tool
to uninstall, simply delete files.
The tool is made available free without any stated or implied warranties or responsibilities as to the results of its use.
Introduction
Simple XML Validator version 2.0 is implemented in VB.NET, it was motivated by the need for quickly checking the validity of our schemas and of our asset files against those schemas.
The original code (version 1.0) was created by Ben Kubicek, you can see the original article at this location.
This version has significant improvements: first it is updated for .NET Framework 2.0 and thus replaces the obsolete objects by the new ones (the new XmlReader and XmlSchemaSet classes as compared to the obsolete XmlValidatingReader class used in version 1.0), second it allows to validate any XML file against any schema from
any location, third the results were made a little more complete and easy to use (however carefully read the important note at the end of the user's guide section).
User's Guide
Simple XML Validator can be use to validate XSD schemas or to validate XML file against a schema, all of which can be located in any directory.
The user interface is simple and intuitive, here is a screenshot of a completed validation:
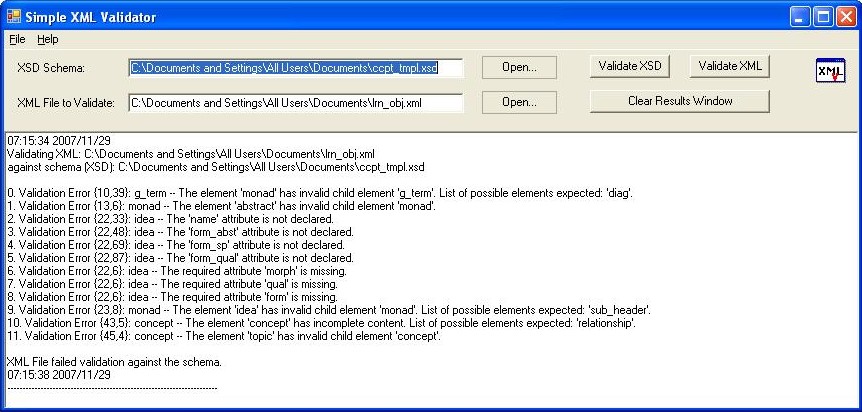
Use the open dialogs to load the desired schema (XSD) file and XML file, the appropriate validation buttons will then become enabled.
To check a schema validity you only need to load the XSD file, however when checking the XML file the schema will also be checked for structural validity
(CAUTION: this is different from being fully validated, for that use the Validate XSD option).
The results window displays the time/date stamp, the files names and paths, the errors list and the final outcome.
Errors are numbered, then qualified (error or warning), next the error placement is given (line number, position within the line),
then the element which causes the error (or in case of an attribute error, the "owner" element) and finally the error message.
IMPORTANT NOTE:
It is important to understand the results from the .NET Framework version 2.0 implementation as opposed to those from version 1.1 of the Framework.
Let's suppose you have the following schema (only the relevant part is shown):
<xs:element name="topic">
<xs:complexType>
<xs:sequence>
<xs:element name="title" type="xs:string" />
<xs:element name="abstract" type="bwi:abstract_type"></xs:element>
<xs:element name="concept" type="bwi:concept_type"></xs:element>
</xs:sequence>
<xs:attribute name="id" type="xs:string" use="required" />
<xs:attribute name="obj" type="xs:string" use="required" />
</xs:complexType>
</xs:element>
<xs:complexType name="abstract_type">
<xs:sequence>
<xs:element name="monad" type="bwi:monad_type"></xs:element>
</xs:sequence>
</xs:complexType>
Since you did not state minOccurs and maxOccurs, you expect each element to appear once and once only in the correct sequence.
Let's assume you now want to validate the following XML (only the relevant fragment is shown):
<topic id="IDAO5I1EIDAP5I1E">
<title>Introduction to Learning Objects</title>
<abstract>
<monad>Of particular interest, is how encapsulation facilitates reuse.</monad>
<monad>Facilitating <g_term id="2">reuse</g_term> of IP is the central theme of this course.</monad>
<monad>This will be the main idea for the remainder of this section.</monad>
</abstract>
<concept>This is the concept for the course...</concept>
</topic>
Since occurences of monad should only be one, it is pretty clear that the second and third occurences will not validate.
Furthermore the element g_term is undefined in the schema. However what will appear as the result of the XmlReader class validation implementation is as follows:
Only the second monad will cause an exception, at that point the children of that second monad (g_term) and the third monad will be ignored
and the reader will jump to the end tag of abstract, thus ignoring these other errors.
While one can discuss the logic followed by Microsoft for these particular objects, it does have a certain positive side: it unclutters the results and since that second monad is
invalid why bother with its children or yet another invalid element after that.
However a major consequence is that after fixing the first round of errors, validation should be ran again,
thus catching subsequent errors which did not appear the first time. For example if we only suppress the second monad, the third one will become the second one and get caught
in this new round of validation (the same it we had suppressed the first one, but then on top of that the g_term error would be caught.
The previous implementation would have listed all the errors as they occured, those interested in this behavior can use the (compiled) version of the tool by Ben Kubicek (note that this version has significant restrictions as to the placement of the XSD file).